

Is HTML Worth Learning?
Many years ago, typesetters in newspaper offices would create the layout for their paper with a collection of metal letters in boxes marked by their sizes. There were large letters used for headlines, smaller letters used for the body of the articles, italic letters for photo captions, and plenty of others. Once these letters were placed in the right spot, they’d be covered in ink and used in a press to roll out large quantities of newspapers.
The fundamentals are the same between typesetting and web layout. Except instead of boxes of letters, browsers use HTML tags to know how to display the page’s content. HTML stands for HyperText Markup Language and uses tags just like typesetters to identify headline letters, body-content letters, photo caption letters, etc.
A tag is a piece of text, surrounded by angled brackets that is read and interpreted by your browser and remains invisible to the reader. For instance, if you write the tag <p> in a block of text, and save the text as an HTML file, when you open it in your browser you’ll find a newline exists where the <p> was placed. Tags define the style of your content.
Each tag has a beginning and an end, or an open and close. Anything between the open and close will be styled by the tag.
The basic syntax of a tag is:
<style> content </style>
The first tag <style> says, “anything after this will have this style.” The second, closing tag </style> says “anything after this will no longer have this style.” Both tags have the same name, both are surrounded by angled brackets, however the closing tag is immediately followed by a blackslash (“/”). This format is the same for all tags in HTML.
You can find thousands of books on how to code in HTML with tags. They range from a complete beginner’s guide of just a couple pages, to thousand-page volumes. Many of these books though have hundreds of tags in them and little context about which tags you’ll actually need versus which ones you’ll use every day as a web coder.
To get an idea of what tags are actually worth knowing, I took the source code from ten randomly selected websites (courtesy of http://www.randomwebsite.net/) and did a count of all the different tags listed on the w3schools’s html 4.01 reference.
Here’s what came back:
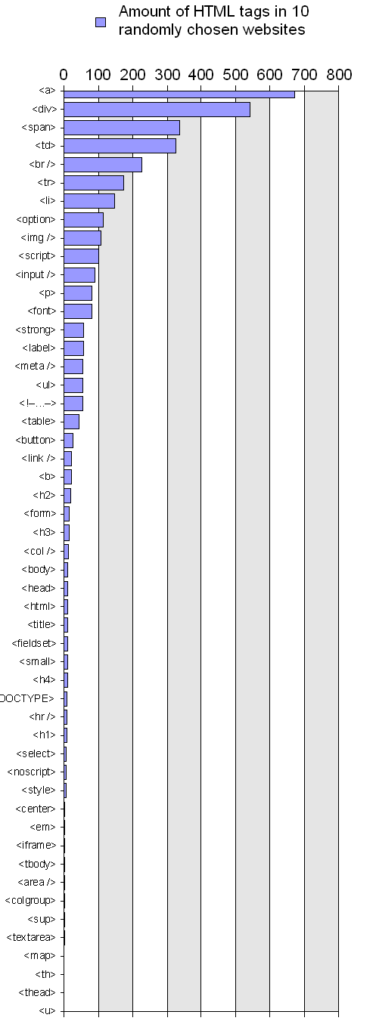
Here are some tags that weren’t even used once:
| <abbr> | <code> | <i> | <pre> |
| <acronym> | <dd> | <ins> | <q> |
| <address> | <del> | <isindex> | <s> |
| <applet> | <dfn> | <kbd> | <samp> |
| <base /> | <dir> | <legend> | <strike> |
| <basefont /> | <dl> | <menu> | <sub> |
| <bdo> | <dt> | <noframes> | <tfoot> |
| <big> | <frame /> | <object> | <tt> |
| <blockquote> | <frameset> | <ol> | <var> |
| <caption> | <h5> | <optgroup> | <xmp> |
| <cite> | <h6> | <param /> |
That’s 43 tags that aren’t even used. So what does this mean? It means that HTML books that treat all tags equally are pretty full of fluff. Why spend your time learning all these extra tags if you’ll only need them once or twice in your career?
Here are the tags that were used on every site:

And here’s how frequently those tags above were used:
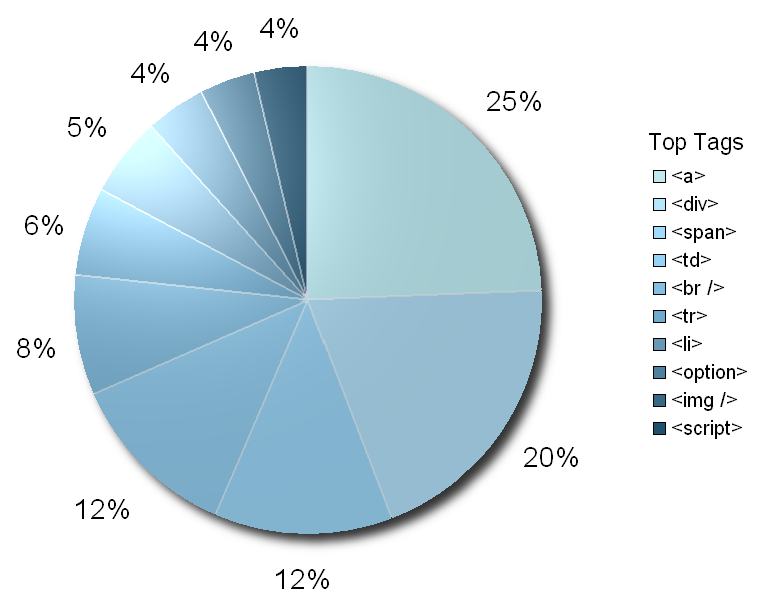
Most web coders probably know how to work with this list of ten tags at least. However, they’d reserve the rest for google when they need them.
HTML and it’s various tags are indeed worth learning if you are looking to become a web developer since all websites fundamentally break down into HTML tags. However, it probably isn’t worth it to study a book of all the different tags and their options since fewer than half the existing available tags ever get used. Instead, just knowing that there are other tools in your toolbox (or tags in your tagbox) that exist, even if unpopular, should give you pause enough to look up those rare tags before trying to shoehorn the more common ones into a project where they don’t belong.


{kind=link}
{kind=link}
{kind=link}
{kind=link}